dropless moe|A self : Tuguegarao • We show how the computation in an MoE layer can be expressed as block-sparse operations to accommodate imbalanced assignment of tokens to experts. We use this . El metro Chile España se ubica en la Av. Irarrázaval, a la altura de la Av. José Pedro Alessandri.Esta estación se encuentra en el subterráneo y se sitúa en la comuna de Ñuñoa.. Pulsando sobre la ficha de Google de la terminal, podrá ubicarla fácilmente en su teléfono móvil. Así mismo, si le resulta más cómodo utilizar el Plus Code se lo mostramos:
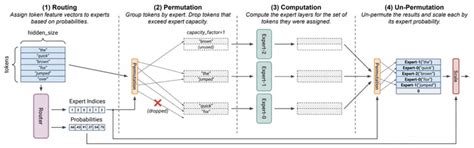
dropless moe,MegaBlocks is a light-weight library for mixture-of-experts (MoE) training. The core of the system is efficient "dropless-MoE" (dMoE, paper) and standard MoE layers. .MegaBlocks is a light-weight library for mixture-of-experts (MoE) training. The core of the system is efficient "dropless-MoE" ( dMoE , paper ) and standard MoE layers. .• We show how the computation in an MoE layer can be expressed as block-sparse operations to accommodate imbalanced assignment of tokens to experts. We use this .
MegaBlocks is a light-weight library for mixture-of-experts (MoE) training. The core of the system is efficient "dropless-MoE" ( dMoE , paper ) and standard MoE layers. .MegaBlocks is a light-weight library for mixture-of-experts (MoE) training. The core of the system is efficient "dropless-MoE" ( dMoE , paper ) and standard MoE layers. MegaBlocks is built on top of Megatron-LM , where we support data, .
In contrast to competing algorithms, MegaBlocks dropless MoE allows us to scale up Transformer-based LLMs without the need for capacity factor or load balancing losses. .
A selfFinally, also in 2022, “Dropless MoE” by Gale et al. reformulated sparse MoE as a block-sparse matrix multiplication, which allowed scaling up transformer models without the .The Mixture of Experts (MoE) models are an emerging class of sparsely activated deep learning models that have sublinear compute costs with respect to their parameters. In .
Abstract: Despite their remarkable achievement, gigantic transformers encounter significant drawbacks, including exorbitant computational and memory footprints during training, as .
dropless moe|A self
PH0 · megablocks · PyPI
PH1 · [2109.10465] Scalable and Efficient MoE Training for Multitask
PH2 · Towards Understanding Mixture of Experts in Deep Learning
PH3 · Sparse MoE as the New Dropout: Scaling Dense and Self
PH4 · MegaBlocks: Efficient Sparse Training with Mixture
PH5 · GitHub
PH6 · Efficient Mixtures of Experts with Block
PH7 · Aman's AI Journal • Primers • Mixture of Experts
PH8 · A self